Implimentation d’un CNN simple
Dans ce notebook on va entrainer pas à pas un réseau de neurones convolutionnel pour faire de la reconnaissance d'objets dans des images.

Remarque “”
Une image est un condensé de données, que l’on appel les pixels.
1. Importation des bibliothèques nécessaires
Comme vous l'avez déjà fait en important TensorFlow et d'autres bibliothèques, assurez-vous d'avoir toutes les bibliothèques requises pour la création du CNN.
import cv2
import numpy as np
import requests
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import sys
import datetime
from tensorflow import keras
from tensorflow.keras.models import Model
import tensorflow as tf
2. Importation des images à partir d’un lien GitHub:
Ce code charge des images de Pikachu et rondoudou à partir d'un lien GitHub en utilisant la bibliothèque requests. L'image est récupérée en streaming, puis convertie en un tableau NumPy pour la manipulation des données. La forme de l'image est affichée pour montrer ses dimensions. Ensuite, l'image est décodée en couleur à l'aide de OpenCV et affichée en utilisant Matplotlib. Pour garantir que les couleurs s'affichent correctement, la conversion de l'espace de couleur de BGR à RGB est effectuée avant l'affichage de l'image. Ainsi, le code permet de visualiser l'image de Pikachu à partir de l'URL fournie de manière claire et simple.
Importation l’images de Pikachu à partir d’un lien GitHub
url_pikachu = r'https://github.com/imadmlf/Convolutional-Neural-Network/blob/main/CNN-Implimentation/%234%20-%20CNN/pikachu.png?raw=true'
resp = requests.get(url_pikachu, stream=True).raw
image_array_pikachu = np.asarray(bytearray(resp.read()), dtype="uint8")
print(f'Shape of the image {image_array_pikachu.shape}')
image_pikachu = cv2.imdecode(image_array_pikachu, cv2.IMREAD_COLOR)
plt.axis('off')
plt.imshow(cv2.cvtColor(image_pikachu, cv2.COLOR_BGR2RGB)) #opencv if BGR color, matplotlib usr RGB so we need to switch otherwise the pikachu will be blue ... O:)
plt.show()

Importation l’images de rondoudou à partir d’un lien GitHub
url_rondoudou = r'https://github.com/imadmlf/Convolutional-Neural-Network/blob/main/CNN-Implimentation/%234%20-%20CNN/rondoudou.png?raw=true'
resp = requests.get(url_rondoudou, stream=True).raw
image_array_rondoudou = np.asarray(bytearray(resp.read()), dtype="uint8")
print(f'Shape of the image {image_array_rondoudou.shape}')
image_rondoudou = cv2.imdecode(image_array_rondoudou, cv2.IMREAD_COLOR)
plt.axis('off')
plt.imshow(cv2.cvtColor(image_rondoudou, cv2.COLOR_BGR2RGB))
plt.show()

3. Affiche les valeurs des pixels des images
1. Redimensionne l'image à une taille de 40x40 pixels en utilisant la méthode d'interpolation bicubique.
2. Convertit l'image redimensionnée en niveaux de gris.
3. Applique un seuillage pour obtenir une image binaire.
4. Affiche les valeurs des pixels de l'image binaire sous forme de tableau 40x40.
res = cv2.resize(image_pikachu , dsize=(40,40), interpolation=cv2.INTER_CUBIC)
print(res.shape)
res = cv2.cvtColor(res,cv2.COLOR_RGB2GRAY) #TO 3D to 1D
print(res.shape)
res = cv2.threshold(res, 127, 255, cv2.THRESH_BINARY)[1]
d = res
for row in range(0,40):
for col in range(0,40):
print('%03d ' %d[row][col],end=' ')
print('')
OUTPUT

plt.imshow(cv2.cvtColor(res, cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.show()
OUTPUT
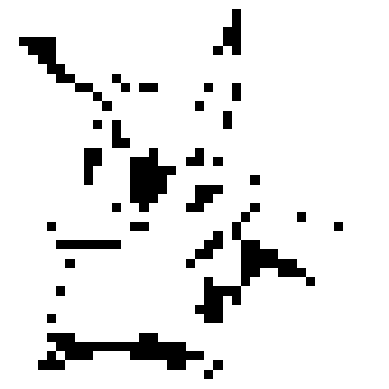
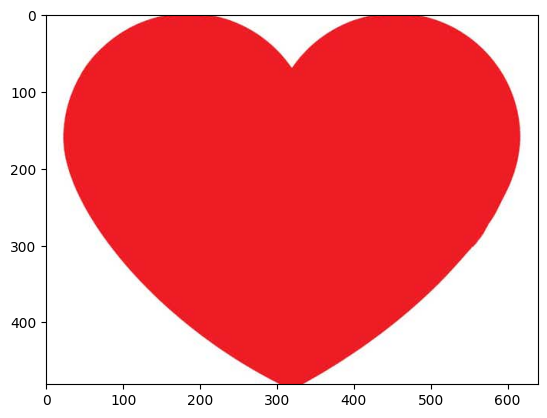
pour bien comprendre, on peut s'appuyer sur une image représentative
Exmple d’une image de cœur
url_heart = r'https://github.com/imadmlf/Convolutional-Neural-Network/blob/main/CNN-Implimentation/%234%20-%20CNN/hearth.jpg?raw=true'
resp = requests.get(url_heart, stream=True).raw
image_array_heart = np.asarray(bytearray(resp.read()), dtype="uint8")
print(f'Shape of the image {image_array_heart.shape}')
image_heart = cv2.imdecode(image_array_heart, cv2.IMREAD_COLOR)
plt.imshow(cv2.cvtColor(image_heart, cv2.COLOR_BGR2RGB)) #opencv if BGR color, matplotlib usr RGB so we need to switch otherwise the pikachu will be blue ... O:)
plt.show()
OUTPUT
res_heart = cv2.resize(image_heart, dsize=(20,20), interpolation=cv2.INTER_CUBIC)
print(res.shape)
res_heart = cv2.cvtColor(res_heart,cv2.COLOR_RGB2GRAY) #TO 3D to 1D
print(res_heart.shape)
res_heart = cv2.threshold(res_heart, 160, 255, cv2.THRESH_BINARY)[1]
d = res_heart
for row in range(0,20):
for col in range(0,20):
print("%03d " % d[row][col], end="")
print("")
OUTPUT

plt.imshow(cv2.cvtColor(res_heart, cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.show()
OUTPUT

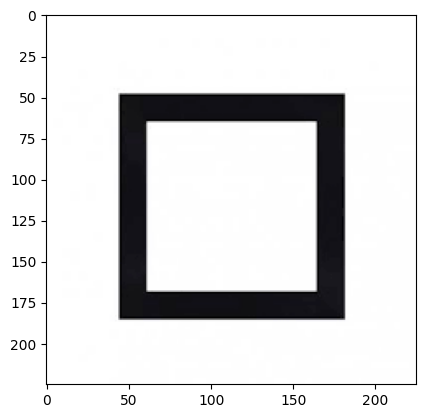
Exmple d’une image de carrée
url_carré = r'https://github.com/imadmlf/Convolutional-Neural-Network/blob/main/CNN-Implimentation/%234%20-%20CNN/carre-noir.png/?raw=true'
resp = requests.get(url_carré, stream=True).raw
image_array_carré = np.asarray(bytearray(resp.read()), dtype="uint8")
print(f'Shape of the image {image_array_carré.shape}')
image_carré = cv2.imdecode(image_array_carré, cv2.IMREAD_COLOR)
plt.imshow(cv2.cvtColor(image_carré, cv2.COLOR_BGR2RGB))
plt.show()
OUTPUT
res_carré = cv2.resize(image_carré, dsize=(20,20), interpolation=cv2.INTER_CUBIC)
print(res.shape)
res_carré = cv2.cvtColor(res_carré,cv2.COLOR_RGB2GRAY) #TO 3D to 1D
print(res_carré.shape)
res_carré = cv2.threshold(res_carré, 160, 255, cv2.THRESH_BINARY)[1]
d = res_carré
for row in range(0,20):
for col in range(0,20):
print("%03d " % d[row][col], end="")
print("")
OUTPUT

plt.imshow(cv2.cvtColor(res_carré, cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.show()
OUTPUT

4. Convertit l’image
Convertit l'image en niveaux de gris en utilisant cv2.imdecode avec l'option cv2.IMREAD_GRAYSCALE.
Applique un seuillage à l'image en utilisant cv2.threshold avec un seuil de 127 pour obtenir une image binaire.
Affiche l'image binaire en utilisant plt.imshow après avoir converti l'image en niveaux de gris en RGB en utilisant cv2.cvtColor(img_bw, cv2.COLOR_BGR2RGB).
La différence principale entre les deux approches réside dans la manière dont l'image est convertie en niveaux de gris et en image binaire. Dans le premier code, l'image est redimensionnée, convertie en niveaux de gris, puis seuillée pour obtenir une image binaire. Dans le deuxième code, l'image est directement convertie en niveaux de gris et ensuite seuillée pour obtenir une image binaire.
#Convert to bw
img_bw = cv2.imdecode(image_array_pikachu, cv2.IMREAD_GRAYSCALE)
(thresh, img_bw) = cv2.threshold(img_bw, 127, 255, cv2.THRESH_BINARY)
plt.axis('off')
plt.imshow(cv2.cvtColor(img_bw, cv2.COLOR_BGR2RGB))
OUTPUT

5. Les filtres de traitement d’images
En traitement d'images, un noyau (ou filtre) est une petite matrice utilisée pour effectuer des opérations de convolution sur une image. La convolution consiste à superposer le noyau sur chaque pixel de l'image et à calculer une nouvelle valeur pour ce pixel en combinant les valeurs des pixels voisins pondérées par les valeurs du noyau.
Dans le cas du noyau d'identité que vous avez défini :
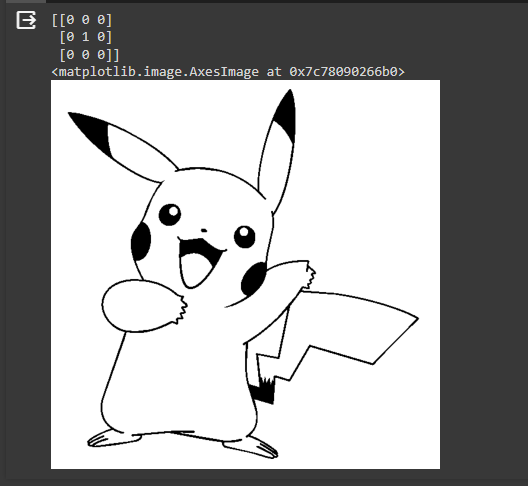
- Le noyau est une matrice 3x3 avec des valeurs spécifiques qui, dans ce cas, sont [[0,0,0],[0,1,0],[0,0,0]]
- Lorsque ce noyau est appliqué à une image en niveaux de gris, il ne modifie pas les valeurs des pixels de l'image car il agit comme une opération d'identité. Chaque pixel conserve sa valeur d'origine.
Résumé
En résumé, l’utilisation d’un noyau d’identité dans le filtrage d’une image signifie que l’image résultante après la convolution avec ce noyau sera identique à l’image d’entrée, car le noyau n’apporte aucun changement aux valeurs des pixels.
#defining an identity kernel, will change nothing because each pixel will remain with is value
kernel = np.matrix([[0,0,0],[0,1,0],[0,0,0]])
print(kernel)
img_1 = cv2.filter2D(img_bw, -1, kernel)
plt.axis('off')
plt.imshow(cv2.cvtColor(img_1, cv2.COLOR_BGR2RGB))
OUTPUT
[[0 0 0]
[0 1 0]
[0 0 0]]
La convolution dans les réseaux de neurones convolutionnels (CNN) consiste à appliquer des filtres ou des noyaux à une image pour mettre en évidence des caractéristiques spécifiques telles que les lignes verticales ou horizontales. Lorsque nous utilisons un noyau de détection de lignes verticales, les pixels à gauche reçoivent moins de poids que ceux à droite, créant ainsi une pente verticale qui met en évidence les lignes verticales dans l'image. De même, un noyau de détection de lignes horizontales mettra en évidence les lignes horizontales en créant une pente horizontale dans l'image.
Voici le code pour appliquer ces noyaux de détection de lignes à une image en utilisant OpenCV :
Définition d’un noyau de détection de lignes verticales
kernel = np.matrix([[-10,0,10],[-10,0,10],[-10,0,10]])
print(kernel)
img_1 = cv2.filter2D(img_bw, -1, kernel)
plt.axis('off')
plt.imshow(cv2.cvtColor(img_1, cv2.COLOR_BGR2RGB))
OUTPUT
[[-10 0 10]
[-10 0 10]
[-10 0 10]]

Définition d’un noyau de détection de lignes horizontales
kernel = np.matrix([[10,10,10],[0,0,0],[-10,-10,-10]])
print(kernel)
img_1 = cv2.filter2D(img_bw, -1, kernel)
plt.axis('off')
plt.imshow(cv2.cvtColor(img_1, cv2.COLOR_BGR2RGB))
OUTPUT
[[ 10 10 10]
[ 0 0 0]
[-10 -10 -10]]

6. Example de convolution
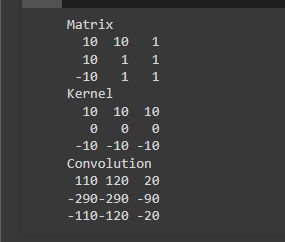
Le code fourni utilise la fonction de convolution convolve de la bibliothèque scipy.ndimage pour appliquer une opération de convolution entre une matrice m et un noyau k. Les valeurs spécifiques de la matrice et du noyau sont définies en tant que matrices 3x3. Ensuite, la fonction de convolution est utilisée avec les paramètres appropriés tels que le mode constant et la valeur de remplissage pour les bords. Le résultat de la convolution est stocké dans la variable c. Le code affiche ensuite la matrice d'origine m, le noyau k et le résultat de la convolution, chacun avec son titre respectif.
En résumé, ce code effectue une opération de convolution entre la matrice et le noyau donnés, illustrant ainsi le processus de convolution en traitement d'images.
from scipy.ndimage import convolve
m = [[10, 10, 1],[10, 1, 1],[-10, 1, 1]]
k = [[10, 10, 10],[0, 0, 0],[-10, -10, -10]]
c= convolve(m, k , mode='constant', cval=0.0)
print('Matrix')
print('\n'.join([''.join(['{:4}'.format(item) for item in row])
for row in m]))
print('Kernel')
print('\n'.join([''.join(['{:4}'.format(item) for item in row])
for row in k]))
print('Convolution')
print('\n'.join([''.join(['{:4}'.format(item) for item in row])
for row in c]))
OUTPUT
k2 = np.matrix(k)
f_min, f_max = k2.min(), k2.max()
filter = (k2 - f_min) / (f_max - f_min)
print(k2.shape)
fig= plt.figure(figsize=(3,3))
plt.imshow(k2)
plt.show
OUTPUT
7. Import dataset
Vous allez avoir toutes vos images sous forme de dataset. J'ai récupéré des images d'un Pikachu et des images d'un Rondoudou à Lorient, mais je n'en ai pas beaucoup. Généralement, pour reconnaître efficacement un objet, il est nécessaire de disposer d'un grand nombre d'images pour l'entraînement du modèle. Dans ce cas, le nombre d'images est limité, mais c'est juste pour que nous puissions comprendre ensemble.
Une fois que j'aurai récupéré l'ensemble des datasets, je les mettrai sous forme d'archive zip que je placerai sur GitHub. Vous pourrez ensuite les récupérer ici en utilisant la ligne de code que je vous fournirai. Nous pourrons alors travailler ensemble sur ces données.
#Import dataset
import pathlib
import os
data_dir = tf.keras.utils.get_file(
"dataset1.zip",
"https://github.com/imadmlf/Convolutional-Neural-Network/blob/main/CNN-Implimentation/%234%20-%20CNN/dataset1.zip?raw=true",
extract=False)
import zipfile
with zipfile.ZipFile(data_dir, 'r') as zip_ref:
zip_ref.extractall('/content/datasets1')
data_dir = pathlib.Path('/content/datasets1/dataset')
print(data_dir)
print(os.path.abspath(data_dir))
OUTPUT

image_count = len(list(data_dir.glob('*/*')))
print(image_count)
OUTPUT
174
8. Préparation des données
Le code commence par définir les paramètres tels que batch_size, img_height, et img_width pour contrôler la taille des lots et des images. Ensuite, il crée un ensemble de données d'entraînement (train_data) en spécifiant le répertoire source data_dir, une division de validation de 20%, une taille d'image de 200x200, et un lot de 3 images. Cet ensemble de données est utilisé pour l'entraînement du modèle.
De même, un ensemble de données de validation (val_data) est créé avec les mêmes paramètres, à l'exception du sous-ensemble qui est défini comme "validation". Cet ensemble de données est destiné à évaluer les performances du modèle sur des données non vues pendant l'entraînement.
Enfin, la variable class_names est utilisée pour stocker les noms de classe des données de validation, ce qui peut être utile pour l'analyse ultérieure. En résumé, ce code permet de charger et de prétraiter des données d'images pour l'entraînement et la validation d'un modèle d'apprentissage automatique.
batch_size = 3
img_height = 200
img_width = 200
training dataset
train_data = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=42,
image_size=(img_height, img_width),
batch_size=batch_size,
)
validation dataset
val_data = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=42,
image_size=(img_height, img_width),
batch_size=batch_size)
class_names = val_data.class_names
print(class_names)
Ce code utilise la bibliothèque Matplotlib pour afficher trois images et leurs étiquettes à partir de l'ensemble de données d'entraînement train_data.
plt.figure(figsize=(10, 10))
for images, labels in train_data.take(1):
for i in range(3):
ax = plt.subplot(1, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
OUTPUT

9. Construire le réseau de neurones
Dans ce code, un modèle de réseau de neurones convolutif est créé en utilisant TensorFlow et Keras. Le modèle est construit en empilant différentes couches les unes sur les autres dans une séquence. Tout d'abord, les images en entrée sont mises à l'échelle en divisant chaque pixel par 255 à l'aide de la couche de prétraitement Rescaling.
Ensuite, quatre couches Conv2D sont ajoutées avec des tailles de noyau de 128, 64, 32 et 16 respectivement, et une fonction d'activation ReLU est appliquée après chaque convolution. Entre les couches Conv2D, des couches de pooling MaxPooling2D sont insérées pour réduire la dimensionnalité des caractéristiques extraites.
Après les quatre couches Conv2D et de pooling, une couche Flatten est utilisée pour aplatir les données en un vecteur unidimensionnel, afin de les passer à travers des couches entièrement connectées. Deux couches Dense sont ajoutées à la fin du modèle, l'une avec 64 neurones et une activation ReLU, et l'autre avec un nombre de neurones égal à num_classes (dans ce cas, 2) et une activation softmax pour la classification finale.
Ce modèle est conçu pour être utilisé dans des tâches de classification d'images où il y a deux classes cibles à prédire. Une fois que le modèle est construit, il peut être compilé et entraîné sur des données d'entraînement pour apprendre à reconnaître et classer les images en fonction des classes spécifiées.
from tensorflow.keras import layers
num_classes = 2
model = tf.keras.Sequential([
layers.experimental.preprocessing.Rescaling(1./255),
layers.Conv2D(128,4, activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64,4, activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32,4, activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(16,4, activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(64,activation='relu'),
layers.Dense(num_classes, activation='softmax')
])
10. Entrainement du réseau de neurones
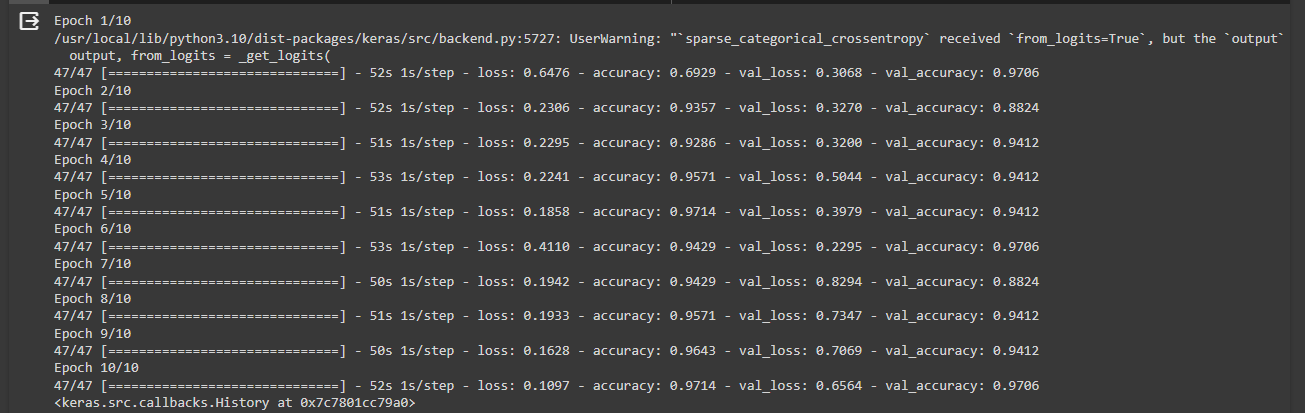
Dans ce code, un modèle de réseau de neurones convolutif est construit en utilisant TensorFlow et Keras. Le modèle est composé de plusieurs couches Conv2D, de couches de pooling MaxPooling2D, d'une couche Flatten et de couches Dense pour la classification. Le modèle est ensuite compilé avec l'optimiseur Adam, la fonction de perte SparseCategoricalCrossentropy et la métrique d'exactitude. Un callback TensorBoard est défini pour permettre la visualisation de la performance du modèle pendant l'entraînement. Une fois le modèle compilé et le callback défini, le modèle peut être entraîné en utilisant ces configurations pour surveiller et enregistrer les métriques d'entraînement et de validation.
model.compile(optimizer='adam',
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'],)
logdir="logs"
tensorboard_callback = keras.callbacks.TensorBoard(log_dir=logdir,histogram_freq=1, write_images=logdir,
embeddings_data=train_data)
model.fit( train_data,validation_data=val_data,epochs=10,callbacks=[tensorboard_callback])
**Pour choisir le meilleur modèle, **
from tensorflow.keras.callbacks import ModelCheckpoint
# Définir le callback ModelCheckpoint pour sauvegarder le meilleur modèle
checkpoint_callback = ModelCheckpoint(filepath='best_model.h5',
monitor='val_accuracy',
verbose=1,
save_best_only=True,
mode='max')
# Entraîner le modèle en utilisant le callback ModelCheckpoint
history = model.fit(train_data,
validation_data=val_data,
epochs=10,
callbacks=[tensorboard_callback, checkpoint_callback])
# Charger le meilleur modèle sauvegardé
best_model = tf.keras.models.load_model('best_model.h5')
11. Les résultats
En résumé, le code importe la fonction `files.upload()` de la bibliothèque `google.colab` pour permettre le téléchargement de fichiers depuis l'ordinateur local vers l'environnement de notebook Google Colab. Les fichiers téléchargés sont stockés dans la variable `file_to_predict` et peuvent être utilisés dans le code pour accéder à ces fichiers. Cela facilite le chargement de données ou d'autres fichiers nécessaires à l'exécution du code dans l'environnement Google Colab.
from google.colab import files
file_to_predict = files.upload()

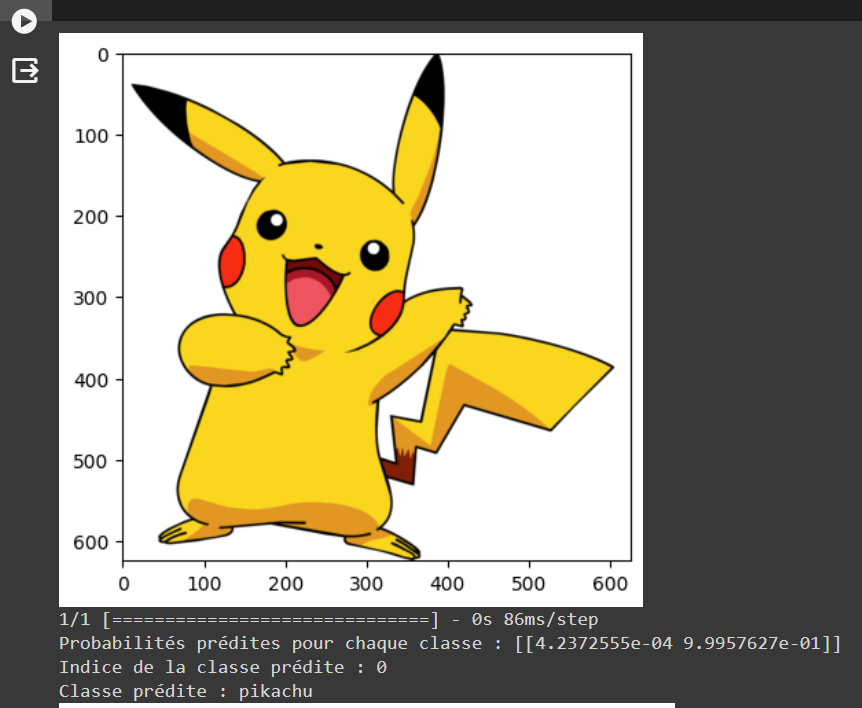
Ce code utilise OpenCV pour lire une image à partir d'un fichier, la redimensionner et l'afficher en utilisant matplotlib. Ensuite, il utilise un modèle de machine learning pré-entrainé pour faire des prédictions sur cette image. Les probabilités prédites pour chaque classe sont imprimées, puis comparées à un seuil de 0,5. Si la probabilité dépasse ce seuil, la classe est prédite comme étant la classe 1, sinon c'est la classe 0. Enfin, le nom de la classe prédite est affiché en se basant sur un tableau de noms de classe prédéfinis.
for file_ in file_to_predict:
image_to_predict = cv2.imread(file_, cv2.IMREAD_COLOR)
plt.imshow(cv2.cvtColor(image_to_predict, cv2.COLOR_BGR2RGB))
plt.show()
img_to_predict = np.expand_dims(cv2.resize(image_to_predict, (200, 200)), axis=0)
# Prédiction avec le modèle
predictions = model.predict(img_to_predict)
# Imprimer les probabilités prédites pour chaque classe
print("Probabilités prédites pour chaque classe :", predictions)
# Comparer les probabilités avec le seuil de 0,3
if predictions[0][0] >= 0.5:
predicted_class_index = 1
else:
predicted_class_index = 0
# Afficher l'indice de la classe prédite
print("Indice de la classe prédite :", predicted_class_index)
# Afficher le nom de la classe prédite
predicted_class_name = class_names[predicted_class_index]
print("Classe prédite :", predicted_class_name)
OUTPUT